Preparing and Importing Data
Before you can analyze data using R, you need to gather it in a format that R can read and then import it as a vector or table. R can read data in many different formats, but the easiest ones to work with are tab or comma delimited files. While you can use a plain text editor to create this data - you must be careful to make sure that every line in the file has the same number of columns or the file will not load correctly. It is much easier to use a spreadsheet program such as Microsoft Excel or Google Documents to gather your data and then export the data from the spreadsheet as a comma or tab delimited file. ((You can also use a scripting language such as PERL to extract raw data, perform some preliminary calculations, and prepare data to be imported into R.)) The first line of your spreadsheet should begin with a header row that describes the type of data found in that column as illustrated in the image to the left. 
This is the point to introduce the first data set we will use for this tutorial: GreekDramaLength.txt (if you want to work with this file, use these links to download the tab delimited file or the comma delimited file). This file contains four columns, one showing the author of each tragedy, one showing the title, one showing the year in which the drama was written. ((The dates for each drama are sourced from ancienthistory.about.com—bl_dramadates.htm.)) Note that in many cases, we don't have records to show exactly when each tragedy was written, so some of these dates are approximate and disputed by scholars. In a document intended to be read by a human, this uncertainty can be indicated by an abbreviation such as 'ca.' or '~'. A computer program like R cannot interpret notations such as these, so they have been stripped out of this data file.
Once this file has been created, you load can load the data into R and begin your statistical explorations. The command you use depends on the format in which you saved your data file. If you saved the file as comma delimited text, use the command:
trag.length <- read.csv(file.choose(), header = TRUE)
If you saved your source data as tab delimited text, use the command:
trag.length <- read.table(file.choose(), sep = "\t", header = TRUE, quote="")
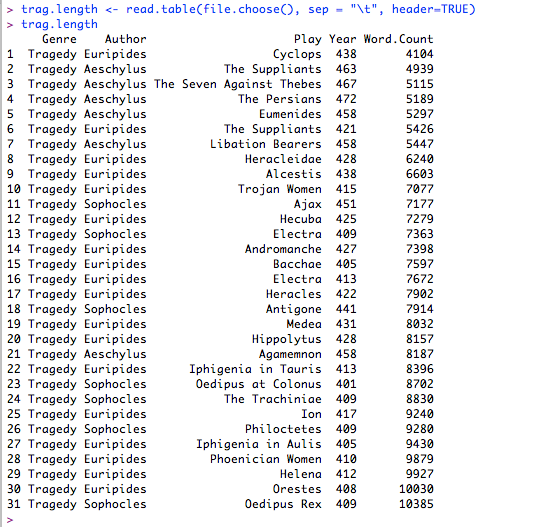 This command brings up a file selection dialogue box that allows you to navigate your hard drive and locate the file that contains your data. Once you select your file, it loads the data into the R environment and assigns it to the variable named
This command brings up a file selection dialogue box that allows you to navigate your hard drive and locate the file that contains your data. Once you select your file, it loads the data into the R environment and assigns it to the variable named trag.length. The , quote="" element of this command tells R to treat quotation marks just like any other character. It is not strictly necessary for this file, but it will be required when we are importing literary texts with quotation marks.
If you are using a version of R running within a Unix terminal on either Mac OSX or a Linux machine, note that the file.choose function is not supported and you will need to enter the path to the file in place of the file.choose function.
You can then verify that the data is available to you by typing trag.length and pressing return. This command prints the contents of the trag.length variable to the screen. If you see results that match the data you have prepared, you are now ready to begin using R to analyze this data.
For this tutorial, you will need to import one additional data sets that contains all of the English words in books nine through twelve of Homer's Odyssey sub-segmented by episode.
Download the Odyssey file and load it into your R environment with the commands:
odyssey.monsters <- read.table(file.choose(), sep = "\t", header = TRUE). After you have loaded in the data set, type odyssey.monsters to see the data in R.
<<-- Previous: The R Environment
Next: Preparing Literary Data -->>